Economics of the AI Supercycle
5 min read
MS&E435 | 1
Where is the $ in AI?
If you’re working/building/funding a business in AI, you should know where the “money is at”.
:::fullwidth
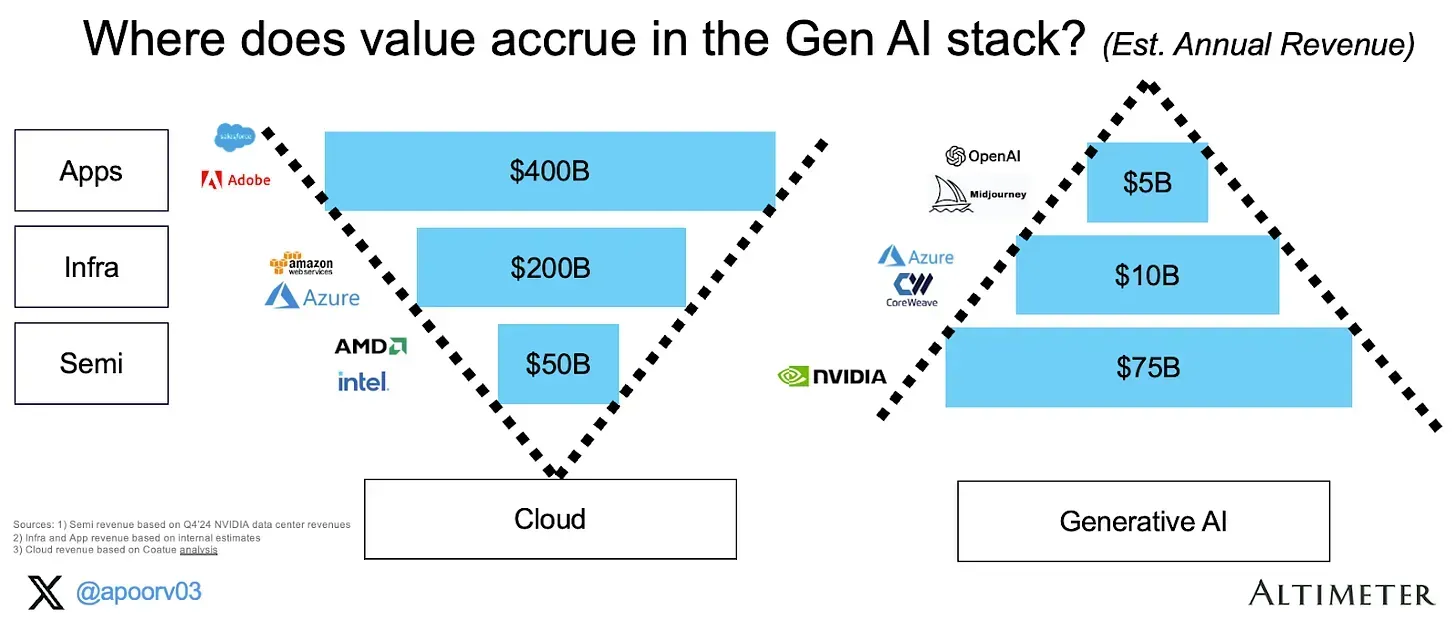 :::
The question that the right-hand side of this chart poses is, you’ve done your data-collection, your pre-training, built data centres and are now serving your LLMs, but are the LLMs making you money? The previous-big-innovation, the “Cloud Computing” looks drastically different. Why so?
One important distinction is that applications in the “cloud” world ran at 80-90% cost margins, incredibly cheap which is not so much true for the AI economy. You have to burn those GPUs to run your applications. Point to be noted, the “semis” layer on the right-hand side is for a period of 5-6 years. You “invest” for the future so that the application margins can grow, and you can realistically serve more/make it cheaper to serve hence profitability margins would grow with time. Unless the hyperscaler (AWS, GCP, Azure) layer has a breakthrough, or the semis layer, there would be quite some time until the AI pyramid inverts. Currently, in all the GPUs NVIDIA sells to this industry, 40% of them are used for inference, and 60% for training. A drastic shift would be when the ratio of inference:training increases.
Currently, the cost margins for NVIDIA are around 75%, whereas most of the apps run on an estimated 0 -> 30% cost margin.
:::
The question that the right-hand side of this chart poses is, you’ve done your data-collection, your pre-training, built data centres and are now serving your LLMs, but are the LLMs making you money? The previous-big-innovation, the “Cloud Computing” looks drastically different. Why so?
One important distinction is that applications in the “cloud” world ran at 80-90% cost margins, incredibly cheap which is not so much true for the AI economy. You have to burn those GPUs to run your applications. Point to be noted, the “semis” layer on the right-hand side is for a period of 5-6 years. You “invest” for the future so that the application margins can grow, and you can realistically serve more/make it cheaper to serve hence profitability margins would grow with time. Unless the hyperscaler (AWS, GCP, Azure) layer has a breakthrough, or the semis layer, there would be quite some time until the AI pyramid inverts. Currently, in all the GPUs NVIDIA sells to this industry, 40% of them are used for inference, and 60% for training. A drastic shift would be when the ratio of inference:training increases.
Currently, the cost margins for NVIDIA are around 75%, whereas most of the apps run on an estimated 0 -> 30% cost margin.
[!QUESTION] Why is the profitability so varied? One could theorise that one player NVIDIA dominates the semi layer. There’s simply no competition, so they can charge whatever they want to.
Where will value accrue in AI?
:::image-group
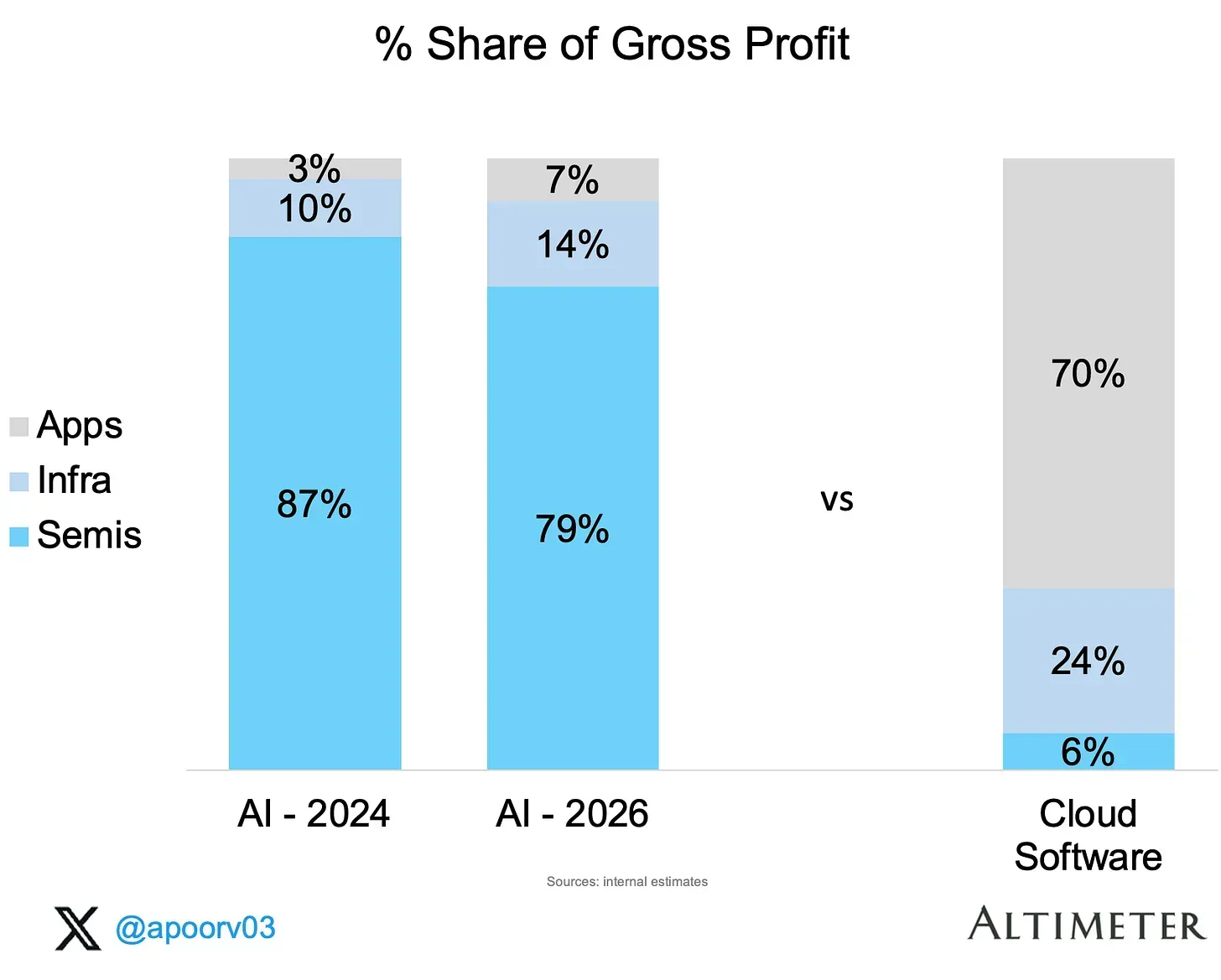 :::
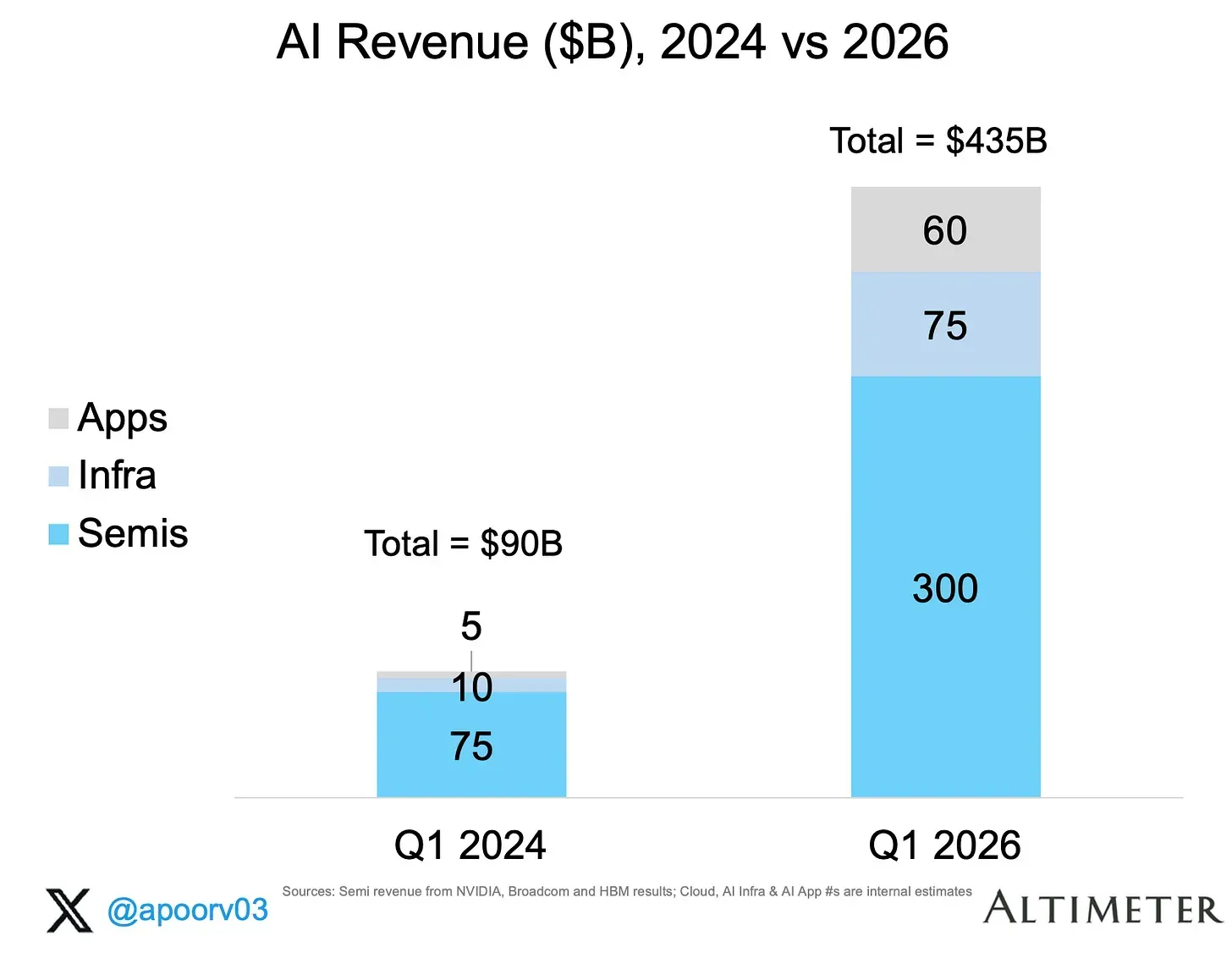
Clearly, there has been a sufficient increase in the revenue going forward into 2026 in the applications-space. Where do consumer applications land in the mainstream application space? Near applications that are relevant to our daily lives like WhatsApp, YouTube, Chrome, or social media like Instagram, Facebook or niche apps like Spotify, Amazon (listed in accordance with number of users).
Answer: ChatGPT has just overtaken Spotify within 2 years of launch. ChatGPT is where you do active questions, does the entirety of population care about knowledge?
:::
Clearly, there has been a sufficient increase in the revenue going forward into 2026 in the applications-space. Where do consumer applications land in the mainstream application space? Near applications that are relevant to our daily lives like WhatsApp, YouTube, Chrome, or social media like Instagram, Facebook or niche apps like Spotify, Amazon (listed in accordance with number of users).
Answer: ChatGPT has just overtaken Spotify within 2 years of launch. ChatGPT is where you do active questions, does the entirety of population care about knowledge?
MS&E435 | 2: Sunny Madra (Groq) and Brad Gerstner
Technology has went from 6% of the GDP from 1990s-2000s to 13-15% of the GDP (US Data).
[!info] What does the contribution of technology to GDP look like for India? As per the FY22 data, the share of the IT-BPM sector in the GDP of India is 7.4%. The number used to be 1.2% in 1998, as per Business Standard India.
AI is expected to bring forth a 10x revolution compared to the Industrial Revolution at 10x the speed. For any token generation, there is a lot and a lot of math. The number of compute cycles it takes to generate a single token is humungous compared to traditional compute applications. The compute scales quadratically with the context length of the model, and linearly with the parameter size $O(L^2d)$. Reasoning models came along which were more voracious with their token usage. Groq and other companies worked on dissecting the inference to make more token-efficient architectures. There’s (a) Prefill and (b) Decode. They worked with NVIDIA to divide the phases into multiple chips.
The Prefill phase is the encoding phase where your entire prompt (with the skills, the system instructions, the context) is processed by the models, converted into embeddings, the KV-cache is built up. Then we talk about the Decode phase, where exactly one token is processed per step. The math operations are incredibly low now, but the memory bandwidth required is insane. To predict a single token, the GPU fetches the entire model weight matrices, and the entire KV cache is fetched, then the prediction for the next token is made. The data has to be moved from the GPU VRAM to SRAM regularly to predict a single token.
All this voodoo is before OpenClaw came into the picture. Now people are spending 1,00$-1,000$ a day on “Agents”. The cost of inference has dropped by 90-99% over the cost of last 2-years. Is it expected to drop? The cost is centred around the supply chain (TSMC). Lithographic technologies is reaching a limit. The models keep getting bigger, the demand is growing up. Difficult to comment, when everything is going in a different not-so-favourable direction. The product is crossing the threshold where millions of self-interested actors are judging for themselves that they do need “Claude Code”, or “Codex” for their work, because the threshold for intelligence for those products has crossed the margin. See how Mythos found a bug in OpenBSD, a large enough codebase that developers couldn’t find in years! It has crossed human capabilities, but can we keep up with the compute? Sam Altman has made 1.3T$ worth of spending commitments with a revenue of 13B$, but, the product has now grown enough to have revenue scaling up exponentially with the demand. Anthropic is generating billions of dollars in revenue per month. The gross margins have gone from highly negative to highly positive with the token consumption growing and consequentially the intelligence delivered to the end-user.
==The more the semiconductor industry innovates, the model makers innovate, which improves the capabilities of the model, which in-turn improves the abilities of everyone in the pipeline to innovate, pivoting towards a reinforcing feedback loop where improvements in one side mutually accelerate one another. The growth continues until one factor in the entire pipeline hits a bottleneck.==
All of this going on in a rapidly changing industry as Anthropic and OpenAI continue to procure more and more compute for their models.